Oracle 12c中的with子句增强
1. 设置 创建测试表。 DROP TABLE test PURGE; CREATE TABLE test AS SELECT 1 AS id FROM dual CONNECT BY level <= 1000000; 2. WITH子句中的函数 WITH子句声明部分可用来定义函数,如下所示。 WITH FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS BEGIN RETURN p_id; END; SELECT with_function(id) FROM test WHERE rownum = 1 / WITH_FUNCTION(ID) ----------------- 1 SQL> 有意思的是,当WITH子句中包含PL/SQL声明时,分号";"不再能用作SQL语句的终止符。如果我们使用它,SQL*Plus会等待更多命令文本输入。即使在官方文档中,也是使用了分号“;”和反斜杠“/”的组合。 从名字解析角度看,WITH子句PL/SQL声明部分定义的函数比当前模式中其他同名对象优先级要高。 3. WITH子句中的过程 即使不被使用,我们也可以在声明部分定义过程。 SET SERVEROUTPUT ON WITH PROCEDURE with_procedure(p_id IN NUMBER) IS BEGIN DBMS_OUTPUT.put_line('p_id=' || p_id); END; SELECT id FROM test WHERE rownum = 1 / ID ---------- 1 SQL> 现实中,如果你打算从声明部分的函数中调用一个过程,你可以在声明部分定义一个过程。 WITH PROCEDURE with_procedure(p_id IN NUMBER) IS BEGIN DBMS_OUTPUT.put_line('p_id=' || p_id); END; FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS BEGIN with_procedure(p_id); RETURN p_id; END; SELECT with_function(id) FROM test WHERE rownum = 1 / WITH_FUNCTION(ID) ----------------- 1 p_id=1 SQL> 4. PL/SQL支持 PL/SQL并不支持该特点。如果视图在PL/SQL中使用将会报编译错误,如下所示。 BEGIN FOR cur_rec IN (WITH FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS BEGIN RETURN p_id; END; SELECT with_function(id) FROM test WHERE rownum = 1) LOOP NULL; END LOOP; END; / FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS * ERROR at line 3: ORA-06550: line 3, column 30: PL/SQL: ORA-00905: missing keyword ORA-06550: line 2, column 19: PL/SQL: SQL Statement ignored ORA-06550: line 5, column 34: PLS-00103: Encountered the symbol ";" when expecting one of the following: loop SQL> 使用动态SQL可以绕过这个限制。 SET SERVEROUTPUT ON DECLARE l_sql VARCHAR2(32767); l_cursor SYS_REFCURSOR; l_value NUMBER; BEGIN l_sql := 'WITH FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS BEGIN RETURN p_id; END; SELECT with_function(id) FROM test WHERE rownum = 1'; OPEN l_cursor FOR l_sql; FETCH l_cursor INTO l_value; DBMS_OUTPUT.put_line('l_value=' || l_value); CLOSE l_cursor; END; / l_value=1 PL/SQL procedure successfully completed. SQL> PL/SQL中将该特点用于静态SQL是未来版本的事情。 5. 性能优势 定义行内PL/SQL代码的原因是为了改善性能。下面创建常规函数来进行比较。 CREATE OR REPLACE FUNCTION normal_function(p_id IN NUMBER) RETURN NUMBER IS BEGIN RETURN p_id; END; / 运行如下测试,测量行内函数查询消耗的时间和CPU。 SET SERVEROUTPUT ON DECLARE l_time PLS_INTEGER; l_cpu PLS_INTEGER; l_sql VARCHAR2(32767); l_cursor SYS_REFCURSOR; TYPE t_tab IS TABLE OF NUMBER; l_tab t_tab; BEGIN l_time := DBMS_UTILITY.get_time; l_cpu := DBMS_UTILITY.get_cpu_time; l_sql := 'WITH FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS BEGIN RETURN p_id; END; SELECT with_function(id) FROM test'; OPEN l_cursor FOR l_sql; FETCH l_cursor BULK COLLECT INTO l_tab; CLOSE l_cursor; DBMS_OUTPUT.put_line('WITH_FUNCTION : ' || 'Time=' || TO_CHAR(DBMS_UTILITY.get_time - l_time) || ' hsecs ' || 'CPU Time=' || (DBMS_UTILITY.get_cpu_time - l_cpu) || ' hsecs '); l_time := DBMS_UTILITY.get_time; l_cpu := DBMS_UTILITY.get_cpu_time; l_sql := 'SELECT normal_function(id) FROM test'; OPEN l_cursor FOR l_sql; FETCH l_cursor BULK COLLECT INTO l_tab; CLOSE l_cursor; DBMS_OUTPUT.put_line('NORMAL_FUNCTION: ' || 'Time=' || TO_CHAR(DBMS_UTILITY.get_time - l_time) || ' hsecs ' || 'CPU Time=' || (DBMS_UTILITY.get_cpu_time - l_cpu) || ' hsecs '); END; / WITH_FUNCTION : Time=45 hsecs CPU Time=39 hsecs NORMAL_FUNCTION: Time=129 hsecs CPU Time=113 hsecs PL/SQL procedure successfully completed. SQL> 从该测试可以看到,行内函数值消耗了普通函数三分之一的时间和CPU。 6. PRAGMA UDF 12c 版本前,人们经常会提到PRAGMA UDF,据说可通过行内PL/SQL来提升性能,同时,允许在SQL语句外定义PL/SQL对象。下列代码用PRAGMA重新定义之前的常规函数。 CREATE OR REPLACE FUNCTION normal_function(p_id IN NUMBER) RETURN NUMBER IS PRAGMA UDF; BEGIN RETURN p_id; END; / 一旦函数被编译,从先前部分运行该函数会产生相当有趣的结果。 SET SERVEROUTPUT ON DECLARE l_time PLS_INTEGER; l_cpu PLS_INTEGER; l_sql VARCHAR2(32767); l_cursor SYS_REFCURSOR; TYPE t_tab IS TABLE OF NUMBER; l_tab t_tab; BEGIN l_time := DBMS_UTILITY.get_time; l_cpu := DBMS_UTILITY.get_cpu_time; l_sql := 'WITH FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS BEGIN RETURN p_id; END; SELECT with_function(id) FROM test'; OPEN l_cursor FOR l_sql; FETCH l_cursor BULK COLLECT INTO l_tab; CLOSE l_cursor; DBMS_OUTPUT.put_line('WITH_FUNCTION : ' || 'Time=' || TO_CHAR(DBMS_UTILITY.get_time - l_time) || ' hsecs ' || 'CPU Time=' || (DBMS_UTILITY.get_cpu_time - l_cpu) || ' hsecs '); l_time := DBMS_UTILITY.get_time; l_cpu := DBMS_UTILITY.get_cpu_time; l_sql := 'SELECT normal_function(id) FROM test'; OPEN l_cursor FOR l_sql; FETCH l_cursor BULK COLLECT INTO l_tab; CLOSE l_cursor; DBMS_OUTPUT.put_line('NORMAL_FUNCTION: ' || 'Time=' || TO_CHAR(DBMS_UTILITY.get_time - l_time) || ' hsecs ' || 'CPU Time=' || (DBMS_UTILITY.get_cpu_time - l_cpu) || ' hsecs '); END; / WITH_FUNCTION : Time=44 hsecs CPU Time=40 hsecs NORMAL_FUNCTION: Time=33 hsecs CPU Time=29 hsecs PL/SQL procedure successfully completed. SQL> 用PRAGMA UDF的独立函数似乎一直比行内函数还快。 我以为从PL/SQL中调用PRAGMA UDF定义的函数会失败,可事实似乎不是这么个情况。 DECLARE l_number NUMBER; BEGIN l_number := normal_function(1); END; / PL/SQL procedure successfully completed. SQL> 7. WITH_PLSQL Hint 如果包含PL/SQL声明部分的查询不是顶级查询,那么,顶级查询必须包含WITH_PLSQL hint。没有该hint,语句在编译时会失败,如下所示。 UPDATE test a SET a.id = (WITH FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS BEGIN RETURN p_id; END; SELECT with_function(a.id) FROM dual); / SET a.id = (WITH * ERROR at line 2: ORA-32034: unsupported use of WITH clause SQL> 加上WITH_PLSQL hint后,语句编译通过且如期运行。 UPDATE /*+ WITH_PLSQL */ t1 a SET a.id = (WITH FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS BEGIN RETURN p_id; END; SELECT with_function(a.id) FROM dual); / 1000000 rows updated. SQL> 8. DETERMINISTIC Hint 就像刘易斯指出的那样,WITH子句中使用函数会阻止发生DETERMINISTIC优化。 SET TIMING ON ARRAYSIZE 15 WITH FUNCTION slow_function(p_id IN NUMBER) RETURN NUMBER DETERMINISTIC IS BEGIN DBMS_LOCK.sleep(1); RETURN p_id; END; SELECT slow_function(id) FROM test WHERE ROWNUM <= 10; / SLOW_FUNCTION(ID) ----------------- 1 1 1 1 1 1 1 1 1 1 10 rows selected. Elapsed: 00:00:10.07 SQL> 9. 标量子查询缓冲 前面部分,我们看到行内函数定义对DETERMINISTIC hint优化上的负面影响。 庆幸的是,标量子查询缓冲并不被同样被影响。 SET TIMING ON WITH FUNCTION slow_function(p_id IN NUMBER) RETURN NUMBER DETERMINISTIC IS BEGIN DBMS_LOCK.sleep(1); RETURN p_id; END; SELECT (SELECT slow_function(id) FROM dual) FROM test WHERE ROWNUM <= 10; / (SELECTSLOW_FUNCTION(ID)FROMDUAL) --------------------------------- 1 1 1 1 1 1 1 1 1 1 10 rows selected. Elapsed: 00:00:01.04 SQL>
通过with子句,我们可以把很多原本需要存储过程来实现的复杂逻辑用一句SQL来进行表达,
在12C中,with的功能又有所增强,在with里可以直接定义一个函数。
比如
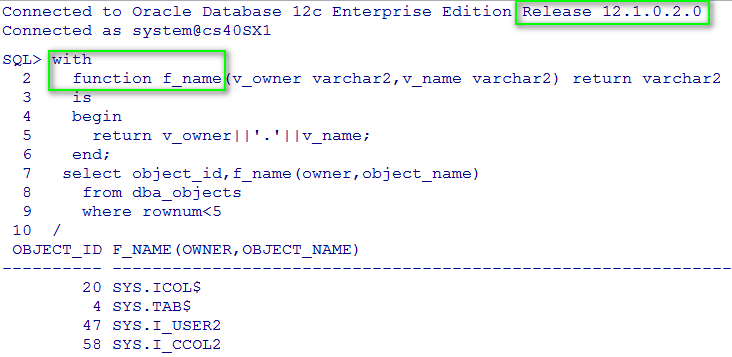
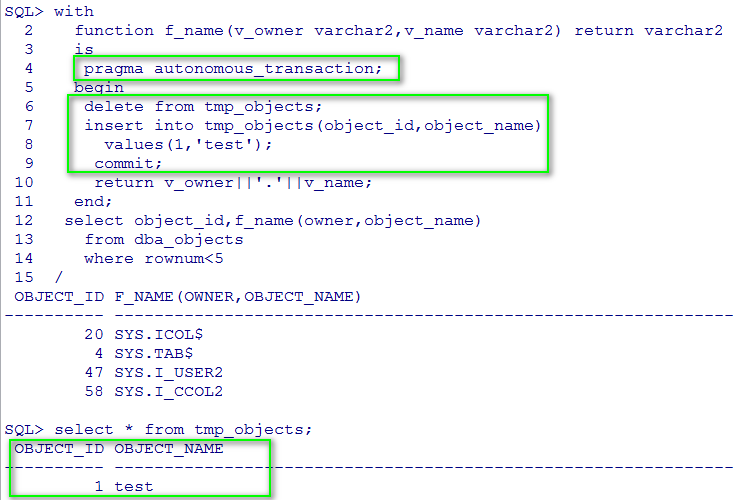
甚至可以支持自治事务函数,在函数中进行DML操作
而在11G中,则直接报错ORA-00905
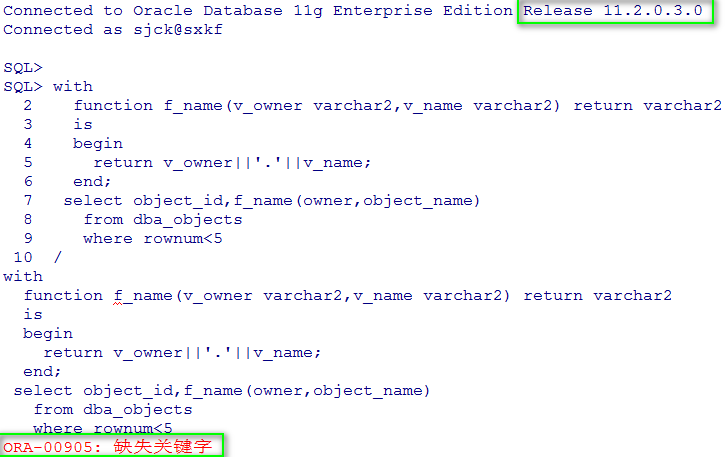
需要注意的是:在function定义的end后面不能跟函数名称
这种语法在查询DG备库查询中可以派上用场,在一个STANDBY备库中,我们不能在只读数据库中创建函数,但通过with子句,我们把函数定义在select语句中,就完美规避了这一问题。
创建测试环境
SQL> conn loge/china@pdb1;
已连接。
SQL> drop table t1 purge;
表已删除。
SQL> create table t1 as
2 select 1 as id from dual
3 connect by level <=1000;
表已创建。
说明:在12c中使用ctas创建表示后不需要在收集信息(EXEC DBMS_STATS.gather_table_stats('LOGE','T1');),将自动收集,可以查询(select * from user_tab_statistics)
在with中使用function
SQL> edit
已写入 file afiedt.buf
1 with
2 function w_function(p_id in number) return number is
3 begin
4 return p_id;
5 end;
6 select w_function(1)
7 from t1
8* where rownum=1
9 /
W_FUNCTION(1)
-------------
1
在with中使用procedure
SQL> edit
已写入 file afiedt.buf
1 with
2 procedure w_procedure (id in number) is
3 begin
4 dbms_output.put_line('id='||id);
5 end;
6 function w_function(p_id in number) return number is
7 begin
8 w_procedure(p_id);
9 return p_id;
10 end;
11 select w_function(id)
12 from t1
13* where rownum=1
SQL> /
W_FUNCTION(ID)
--------------
1
SQL> set serveroutput on
SQL> /
W_FUNCTION(ID)
--------------
1
id=1
PLSQL的支持,此示例比较两个函数性能
1 CREATE OR REPLACE FUNCTION n_function(p_id IN NUMBER) RETURN NUMBER IS
2 BEGIN
3 RETURN p_id;
4* END;
SQL> /
函数已创建。
-- SET SERVEROUTPUT ON
DECLARE
l_time PLS_INTEGER;
l_cpu PLS_INTEGER;
l_sql VARCHAR2(32767);
l_cursor SYS_REFCURSOR;
TYPE t_tab IS TABLE OF NUMBER;
l_tab t_tab;
BEGIN
l_time := DBMS_UTILITY.get_time;
l_cpu := DBMS_UTILITY.get_cpu_time;
l_sql := 'WITH
FUNCTION w_function(p_id IN NUMBER) RETURN NUMBER IS
BEGIN
RETURN p_id;
END;
SELECT w_function(id)
FROM t1';
OPEN l_cursor FOR l_sql;
FETCH l_cursor
BULK COLLECT INTO l_tab;
CLOSE l_cursor;
DBMS_OUTPUT.put_line('W_FUNCTION : ' ||
'Time=' || TO_CHAR(DBMS_UTILITY.get_time - l_time) || ' hsecs ' ||
'CPU Time=' || (DBMS_UTILITY.get_cpu_time - l_cpu) || ' hsecs ');
l_time := DBMS_UTILITY.get_time;
l_cpu := DBMS_UTILITY.get_cpu_time;
l_sql := 'SELECT n_function(id)
FROM t1';
OPEN l_cursor FOR l_sql;
FETCH l_cursor
BULK COLLECT INTO l_tab;
CLOSE l_cursor;
DBMS_OUTPUT.put_line('N_FUNCTION: ' ||
'Time=' || TO_CHAR(DBMS_UTILITY.get_time - l_time) || ' hsecs ' ||
'CPU Time=' || (DBMS_UTILITY.get_cpu_time - l_cpu) || ' hsecs ');
END;
/
结果:
W_FUNCTION : Time=1 hsecs CPU Time=2 hsecs
N_FUNCTION: Time=8 hsecs CPU Time=3 hsecs
PL/SQL 过程已成功完成。
WITH_PLSQL提示,大小写不敏感
SQL> update /*+ WITH_PLSQl */ t1 a
2 set a.id=(with
3 function w_function(p_id in number) return number is
4 begin
5 return p_id;
6 end;
7 select w_function(a.id)
8 from dual);
9 /
已更新 1000 行。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/26736162/viewspace-2220101/,如需转载,请注明出处,否则将追究法律责任。


