有两种方式:
- 使用win32com
- 使用docx
1.使用win32com扩展包
只对windows平台有效
# coding=utf-8
import win32com
from win32com.client import Dispatch, DispatchEx
word = Dispatch('Word.Application') # 打开word应用程序
# word = DispatchEx('Word.Application') #启动独立的进程
word.Visible = 0 # 后台运行,不显示
word.DisplayAlerts = 0 # 不警告
path = 'G:/WorkSpace/Python/tmp/test.docx' # word文件路径
doc = word.Documents.Open(FileName=path, Encoding='gbk')
# content = doc.Range(doc.Content.Start, doc.Content.End)
# content = doc.Range()
print '----------------'
print '段落数: ', doc.Paragraphs.count
# 利用下标遍历段落
for i in range(len(doc.Paragraphs)):
para = doc.Paragraphs[i]
print para.Range.text
print '-------------------------'
# 直接遍历段落
for para in doc.paragraphs:
print para.Range.text
# print para #只能用于文档内容全英文的情况
doc.Close() # 关闭word文档
# word.Quit #关闭word程序
2.使用docx扩展包
优点:不依赖操作系统,跨平台
安装:
pip install python-docx
参考文档: https://python-docx.readthedocs.io/en/latest/index.html
代码:
import docx def read_docx(file_name): doc = docx.Document(file_name) content = '\n'.join([para.text for para in doc.paragraphs]) return content
创建表格
# coding=utf-8
import docx
doc = docx.Document()
table = doc.add_table(rows=1, cols=3, style='Table Grid') #创建带边框的表格
hdr_cells = table.rows[0].cells # 获取第0行所有所有单元格
hdr_cells[0].text = 'Name'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
# 添加三行数据
data_lines = 3
for i in range(data_lines):
cells = table.add_row().cells
cells[0].text = 'Name%s' % i
cells[1].text = 'Id%s' % i
cells[2].text = 'Desc%s' % i
rows = 2
cols = 4
table = doc.add_table(rows=rows, cols=cols)
val = 1
for i in range(rows):
cells = table.rows[i].cells
for j in range(cols):
cells[j].text = str(val * 10)
val += 1
doc.save('tmp.docx')
读取表格
# coding=utf-8
import docx
doc = docx.Document('tmp.docx')
for table in doc.tables: # 遍历所有表格
print '----table------'
for row in table.rows: # 遍历表格的所有行
# row_str = '\t'.join([cell.text for cell in row.cells]) # 一行数据
# print row_str
for cell in row.cells:
print cell.text, '\t',
print
相关样式参考: https://python-docx.readthedocs.io/en/latest/user/styles-understanding.html
使用PYTHON编辑和读取WORD文档
python调用word接口主要用到的模板为python-docx,基本操作官方文档有说明。
python-docx官方文档地址
使用python新建一个word文档,操作就像文档里介绍的那样:
from docx import Document
from docx.shared import Inches
document = Document()
document.add_heading('Document Title', 0) #插入标题
p = document.add_paragraph('A plain paragraph having some ') #插入段落
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='IntenseQuote')
document.add_paragraph(
'first item in unordered list', style='ListBullet'
)
document.add_paragraph(
'first item in ordered list', style='ListNumber'
)
document.add_picture('monty-truth.png', width=Inches(1.25)) #插入图片
table = document.add_table(rows=1, cols=3) #插入表格
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for item in recordset:
row_cells = table.add_row().cells
row_cells[0].text = str(item.qty)
row_cells[1].text = str(item.id)
row_cells[2].text = item.desc
document.add_page_break()
document.save('demo.docx') #保存文档
读取和编辑一个已有的word文档,只需在一开始添加上文件路径就行了,如下:
from docx import Document
from docx.shared import Inches
document = Document('demo.docx') #打开文件demo.docx
for paragraph in document.paragraphs:
print(paragraph.text) #打印各段落内容文本
document.add_paragraph(
'Add new paragraph', style='ListNumber'
) #添加新段落
document.save('demo.docx') #保存文档
如果是想读取其中的图片或是更复杂地编辑,首先我们需要先来认识下docx文档的格式组成:
docx是Microsoft Office2007之后版本使用的,用新的基于XML的压缩文件格式取代了其目前专有的默认文件格式,在传统的文件名扩展名后面添加了字母“x”(即“.docx”取代“.doc”、“.xlsx”取代“.xls”、“.pptx”取代“.ppt”)。
docx格式的文件本质上是一个ZIP文件。将一个docx文件的后缀改为ZIP后是可以用解压工具打开或是解压的。事实上,Word2007的基本文件就是ZIP格式的,他可以算作是docx文件的容器。
docx 格式文件的主要内容是保存为XML格式的,但文件并非直接保存于磁盘。它是保存在一个ZIP文件中,然后取扩展名为docx。将.docx 格式的文件后缀改为ZIP后解压, 可以看到解压出来的文件夹中有word这样一个文件夹,它包含了Word文档的大部分内容。而其中的document.xml文件则包含了文档的主要文本内容。
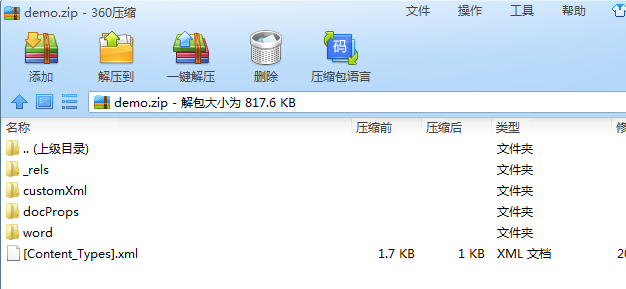
word目录下:

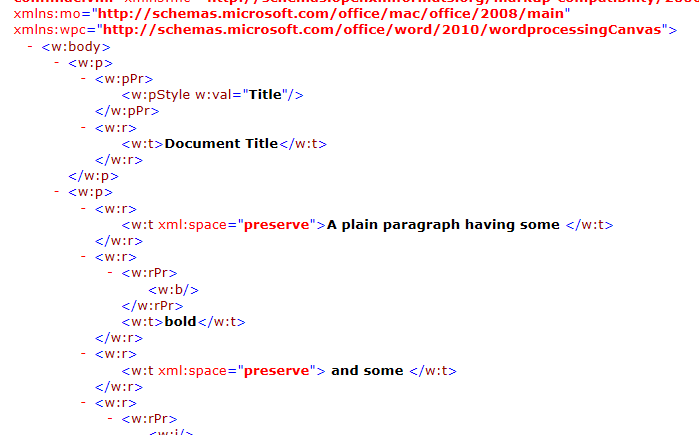
document.xml文件内容:
media目录下存放word文档中插入的图片:
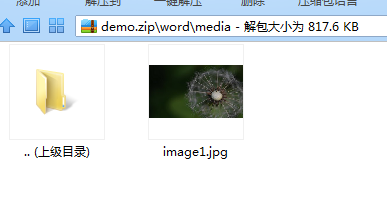
所以,我们可以使用手工的方法编辑文件document.xml来对该word文档内容进行编辑,或是提取文档media中图片文件的方式来提取该word文档中所插入的所有图片。
import zipfile
f=zipfile.ZipFile('demo.docx','r')
for filename in f.namelist():
f.extract(filename)




