目录
一、Hash基本概念
1.1 散列函数
(1) 除法散列法(除留余数法)
(2) 平方散列法(平方取中法)
(3) 斐波那契(Fibonacci)散列法
1.2 解决hash冲突
二、C++中Hash数据结构引入的发展历史
2.1 下面是摘自《Boost程序库完全开放指南》
2.2 下面一段摘自《C++标准库扩展权威指南》
三、各种库对Hash的实现
3.1 SGI STL中提供提供的与hash相关的数据结构
(1) hash_set 容器
(2) hash_map容器
(3) hash_multiset与hash_multimap
(4) hash函数
3.2 TR1(C++11)中提供的与hash相关的数据结构
(1) 散列集合(各类set)简介
(2) 散列集合(各类set)用法
(3) 散列映射(各类map)简介
(4) 散列映射(各类map)的用法
(5) TR1中提供了一个函数对象hash, 可以进行映射.
(6) 如何支持自定义类型
(7) unordered库的内部结构
一、Hash基本概念散列表 Hash Table由散列函数所产生的一种数据结构,是一种非常重要的数据结构. 散列函数(或称 Hash函数)是一种特殊的映射函数。
散列表(哈希表、hash表)是用于存储动态集的一种非常有效的数据结构。通过散列函数h(key)的计算结果,直接得到key关键字表示的元素的存储位置。散列技术中,可能会有两个不同的key1和key2,通过h(key)计算得到的地址如果是一样的,就发生了冲突。散列技术中 哈希函数h(key)的设计 和 哈希冲突如何解决是hash中最关键的两个问题。
1.1 散列函数散列函数要求(1)能快速的计算;(2) 计算结果分布要均匀。(hash function 设计的一条主要原则是:尽量让不同的key算出的结果不同。)
散列函数有如下几种常用的:(1) 除留余数法;(2) 平方取中法;(3) 折叠法;(4) 数字分析法。
(1) 除法散列法(除留余数法)最直观的一种,上图使用的就是这种散列法,公式:
index = value % 16
学过汇编的都知道,求模数其实是通过一个除法运算得到的,所以叫"除法散列法"。
(2) 平方散列法(平方取中法)求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式:
index = (value * value) >> 28
如果数值分配比较均匀的话这种方法能得到不错的结果,但还有个问题,value如果很大,value * value会溢出的,但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取index。
(3) 斐波那契(Fibonacci)散列法平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。
(1),对于16位整数而言,这个乘数是40503
(2),对于32位整数而言,这个乘数是2654435769
(3),对于64位整数而言,这个乘数是11400714819323198485
这几个"理想乘数"是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列.
对我们常见的32位整数而言,公式:
index = (value * 2654435769) >> 28
1.2 解决hash冲突解决冲突的方法有:
- (1) 拉链法 (开散列法):采用 linked list, 冲突的时候就在每个位置(数组)上往下挂(链表)。
- (2) 开地址法 (闭散列法):有的地方也称 开放定址法(发生冲突,继续寻找下一块未被占用的存储地址;或者说 你占了我的位置,我就去别的(下一个+1 或者 + 10)位置。)
拉链法是通过在各地址构建一个链表来解决多元素同地址的问题。
开地址法根据探查序列的不同,又分为(1)线性探查法;(2) 二次探查法;(3) 双散列法。等,其中线性探查法会发生基本聚集,为解决基本聚集采用二次探查法,不过其也会发生二次聚集,双散列法可消除二次聚集。
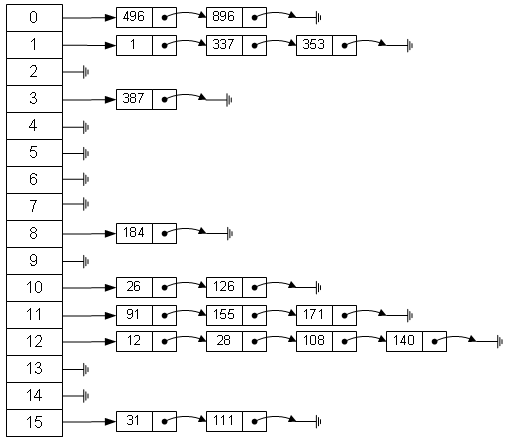
C++对这种数据结构提供了很好的支持。
现代C++最主要的一个特点就是使用STL. STL是C++标准化时所产生的一个非常好的标准模板库. 模板编程带来了C++编程的一个变革. 但是STL的制定还是花费了很长的时间的. 在制定STL的过程中, 曾经有C++标准委员会的委员提出将Hash数据结构加入到STL中,但是,该提案提出的时间比较晚, C++标准委员会不想再将标准完成的时间拖延下去, 所以没有将Hash加入到最初的STL中去. 所以在最初的STL中, 我们只能看到vector, list, set, map 等容器. 但是之后的hash相关的容器加入到了C++的TR1库中去了。 TR1 库是准备在C++0x标准时转化为新的C++标准. 现在新的C++标准已经制定完毕, 是C++11. Hash相关的数据结构也已经从TR1中加入。
(C++ TR1: 全称Technical Report 1,是针对C++标准库的第一次扩展。即将到来的下一个版本的C++标准c++0x会包括它,以及一些语言本身的扩充。tr1包括大家期待已久的smart pointer,正则表达式以及其他一些支持范型编程的内容。草案阶段,新增的类和模板的名字空间是std::tr1)
其实在hash相关的容器进入TR1之前, C++编译器的其他厂商就已经实现了自己的hash容器了. 一般这些容器的命名都是hash_set 或hash_map, 这其中最著名的就是SGI 的STL中所实现的hash容器. 其实这也导致了以后C++标准中对hash容器命名的变化. 为了与之前的名称区别开来, C++标准委员会将标准中的容器命名为unordered_set和unordered_map.
C++还有一个比较著名库是boost库, 其实C++标准中的hash容器都是从boost中转化来的.
2.1 下面是摘自《Boost程序库完全开放指南》


SGI STL中提供了4个容器: hash_set, hash_map, hash_multiset, hash_multimap
还有一个hash函数:hash
在linux和Windows平台上, 对SGISTL的使用有些差别:
在Linux下g++的形式:
头文件:: #include
命名空间:: using namespace __gnu_cxx;
使用方法上和map没有什么大的区别,
#include
using namespace __gnu_cxx;
hash_map obj;
hash_map::iterator iter = obj.begin();在Windows下VC++的形式:
和map的使用方法一样,没有命名空间,直接#include 就可以使用了,就像直接#include 一样。
(1) hash_set 容器容器声明: hash_set
简单的示例程序如下:
#include
#include
#include
using namespace std;
using namespace __gnu_cxx;
struct eqstr
{
bool operator()(const char* s1, const char* s2) const
{
return strcmp(s1, s2) == 0;
}
};
void lookup(const hash_set& Set, const char* word)
{
hash_set::const_iterator it
= Set.find(word);
cout
关注
打赏


