

致力于分享量化策略,培训视频,Python,算法研究等相关内容。
什么是过度拟合过度拟合最初是统计学数据挖掘领域中的概念, 现在机器学习、量化策略领域里也有重要的地位。过度拟合指的是调优一个复杂模型(变量多的模型)去完美拟合历史事件样本,结果模型缺乏预测未来事件的能力。历史样本数越少,模型越复杂, 过度拟合越容易。
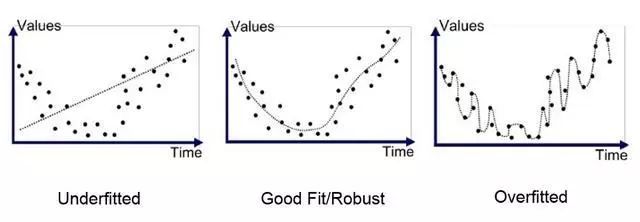
欠拟合(高偏差,低方差)与过拟合(低偏差,高方差)的图
知识点:过拟合:过分依赖训练数据
欠拟合:未能学习训练数据中的关系
高方差:模型根据训练数据显着变化
高偏差:对模型的假设不够导致忽略训练数据过拟合和欠拟合导致测试集的泛化性差;
一个验证集模型校正可以防止过拟合; 1.参数的调优和验证测试不应该用同一个数据集(如下图);

调优集与验证集同一数据集合(过度拟合)
2.参数的调优与验证分别采用不同的数据集合
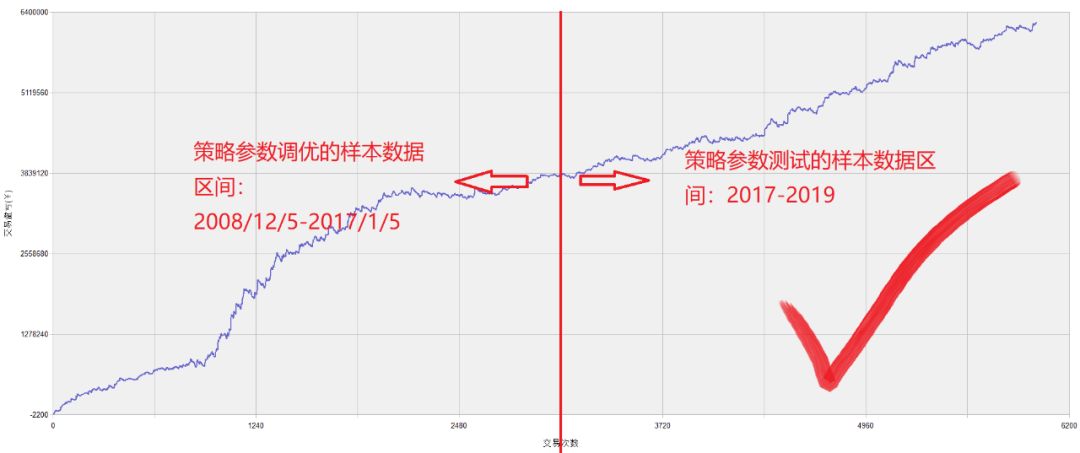
调优集与验证集分别采用不同的数据集合(正确调优)
SF08策略优化参数是调优集与验证集分别采用不同的数据集合进行计算,最终得到了合理的策略参数,拒绝过度优化,回归策略真实的绩效!
PS:参数调优使用的是17年前数据,验证测试是17年后数据;
策略提供四平台源码:MC,金字塔,TB,文华8
策略思想:1.使用变量将KD的快慢均线交叉点记录,然后获取上次交叉到本次交叉之间的周期数。
2.计算此周期内的高低点,当价格突破交叉后的高低点时进场;3.采用短距吊灯移动线离场;
策略版本:股指和商品双版本;
应用周期:商品15分钟,股指5分钟;
交易成本:1.5%%,开平各1滑跳(2跳);
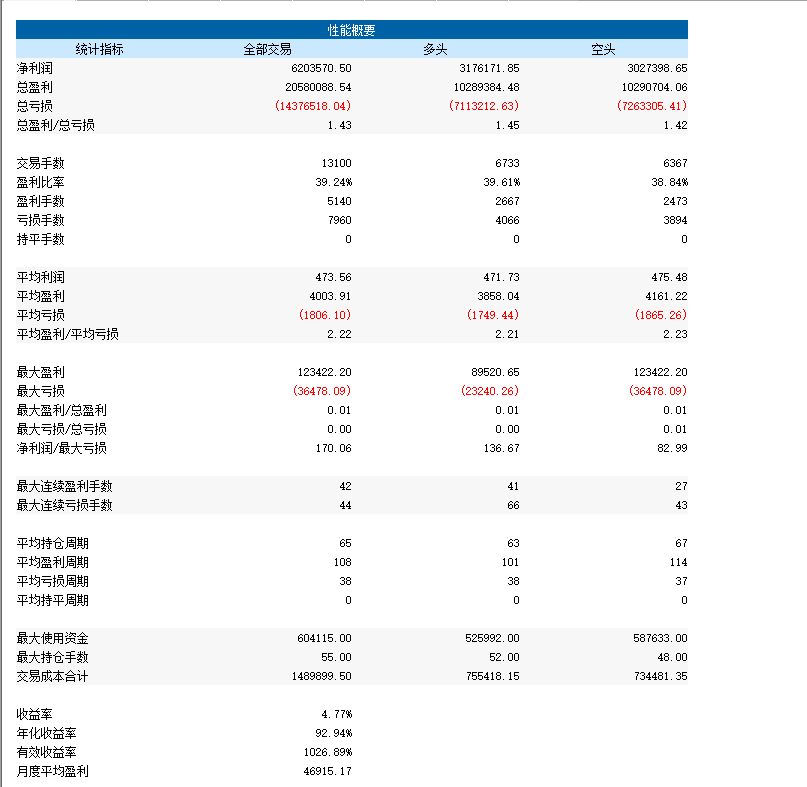
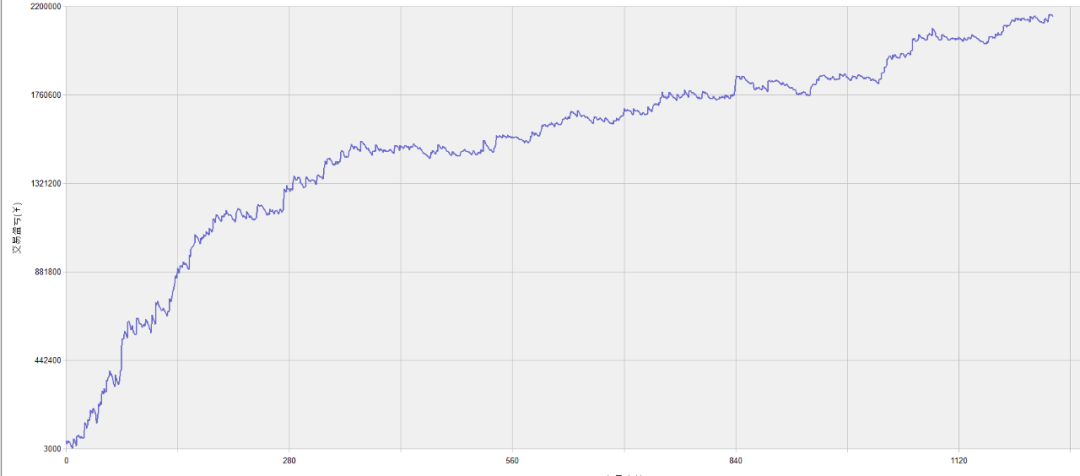
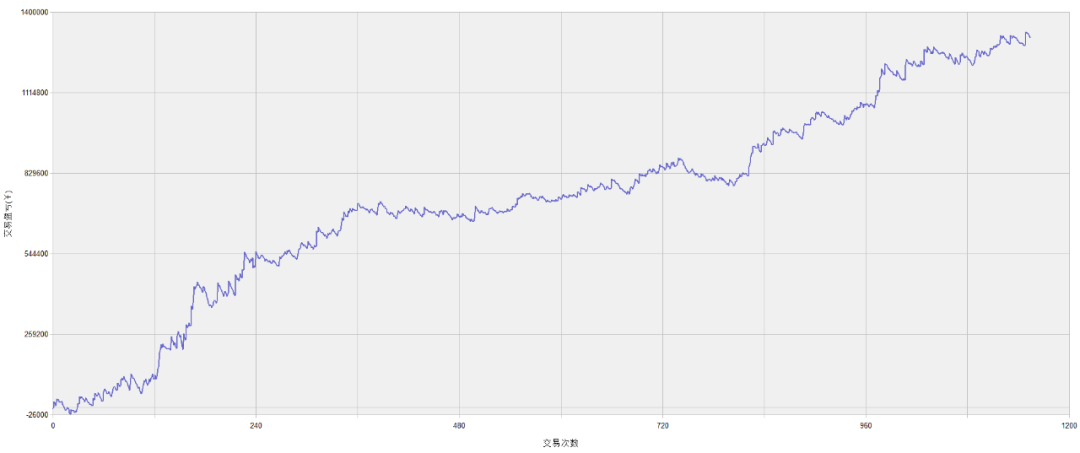
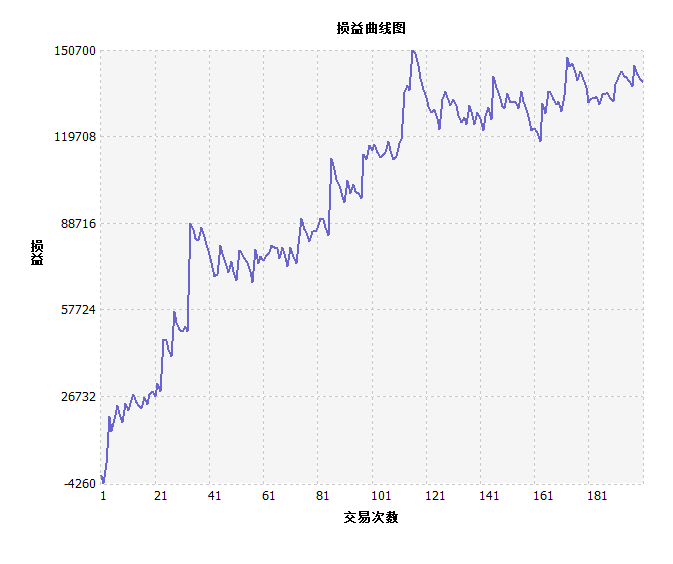
SF08策略绩效如下: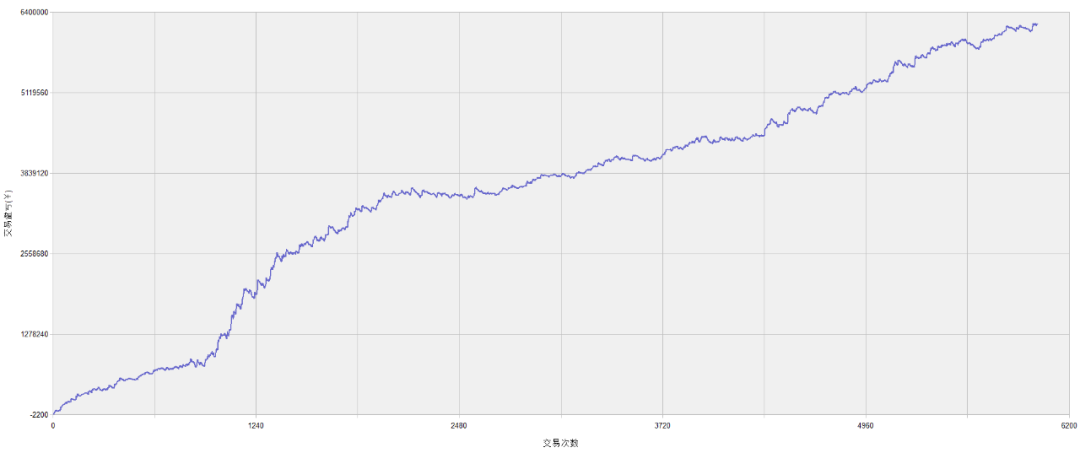

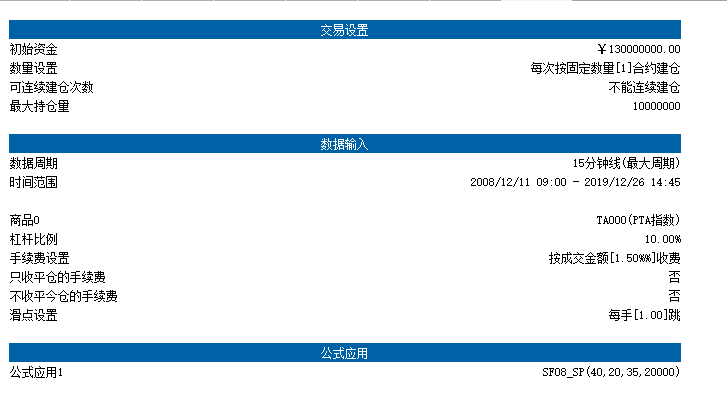
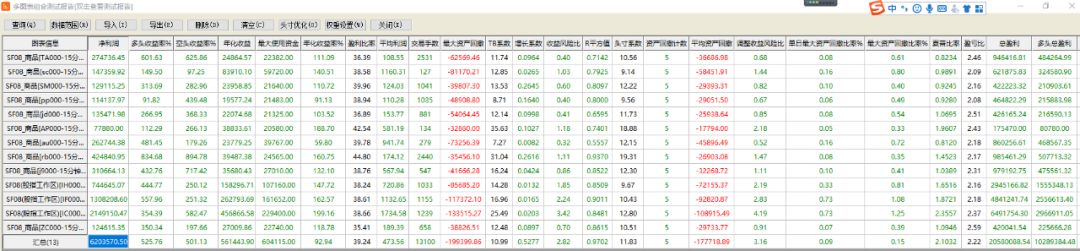
IC
IF
IH
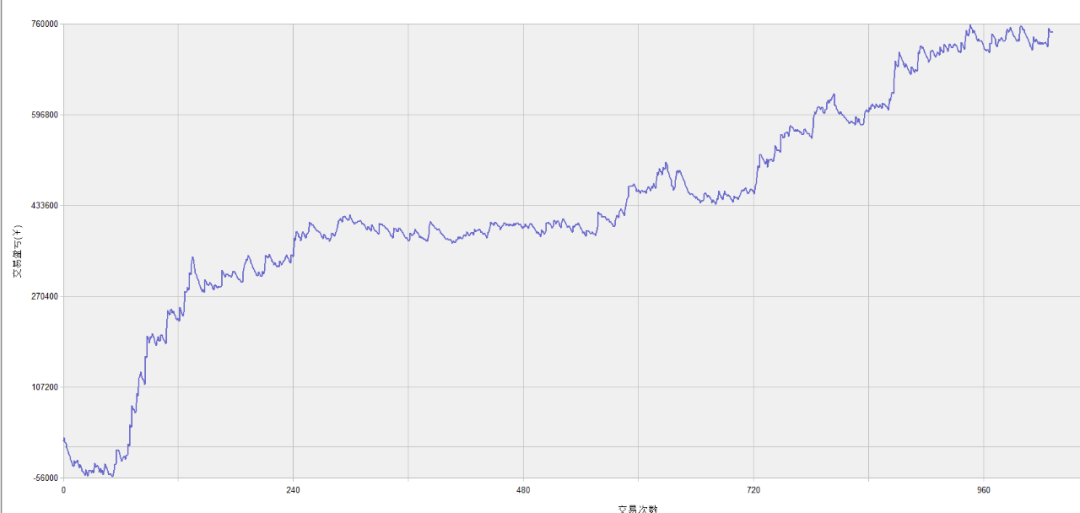
苹果
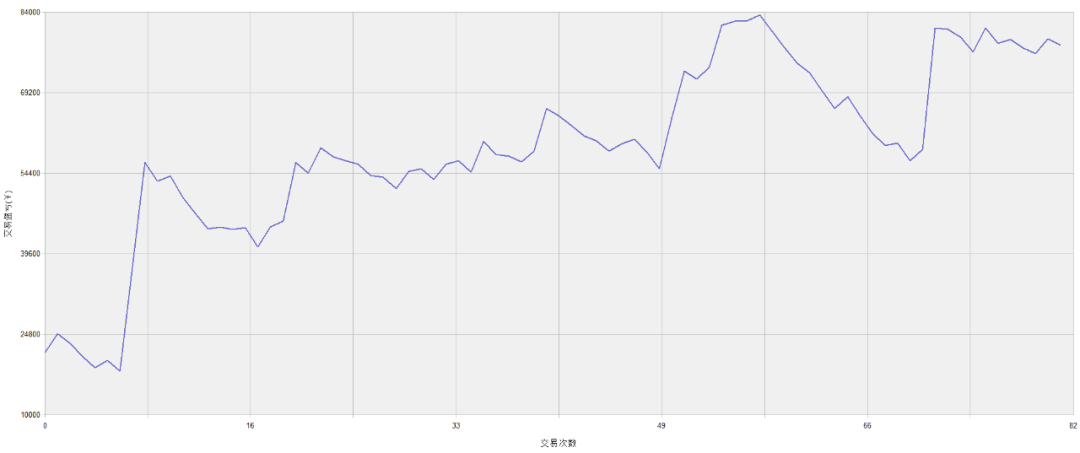
螺纹
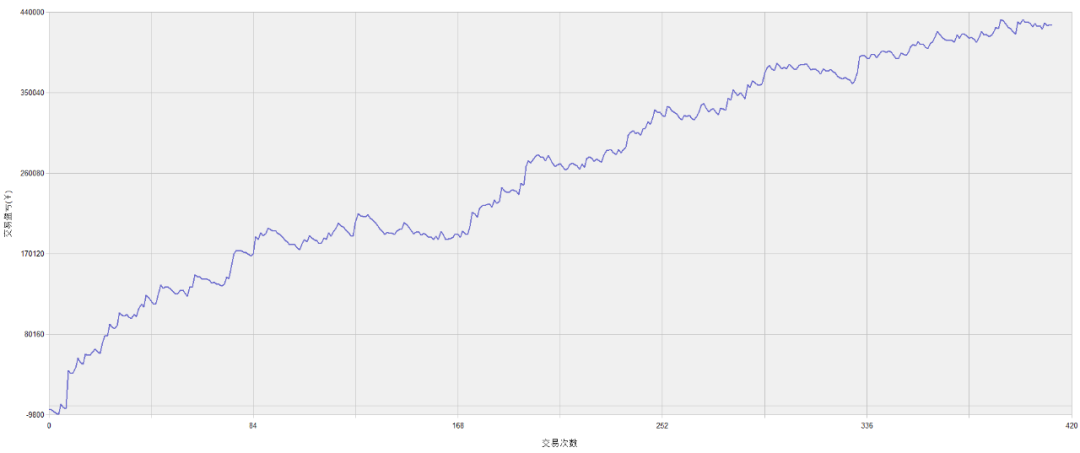
焦炭
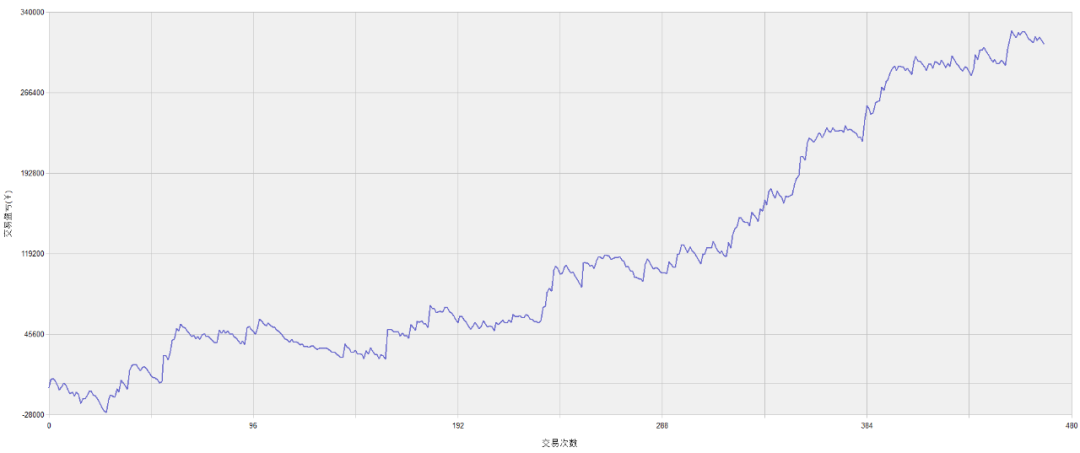
动力煤
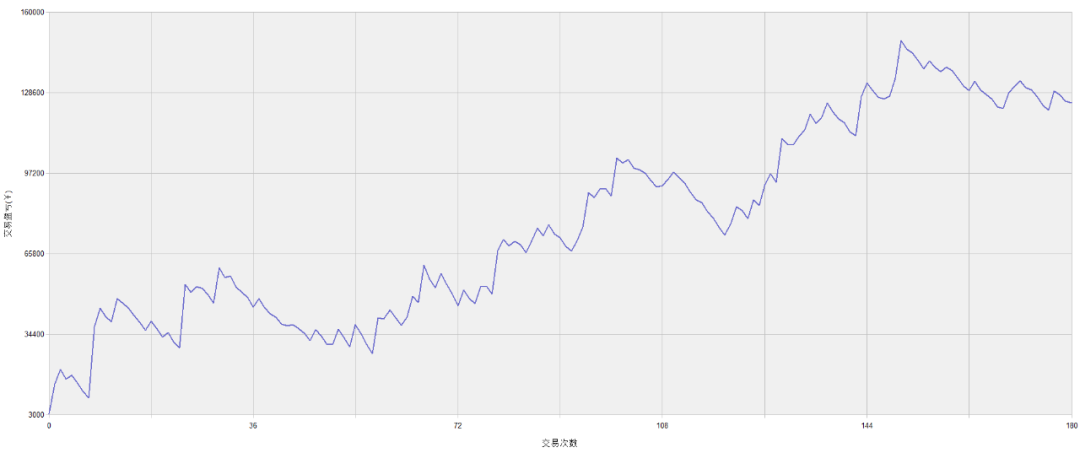
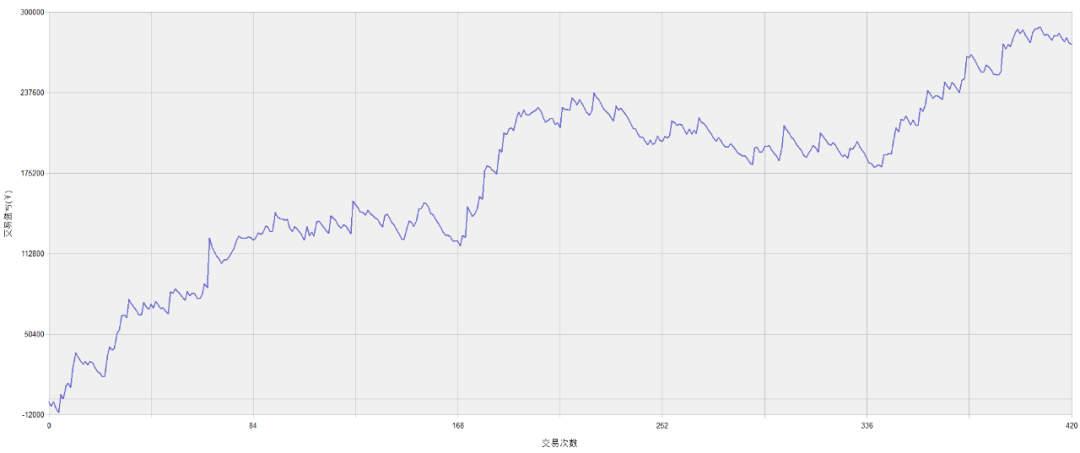
PTA
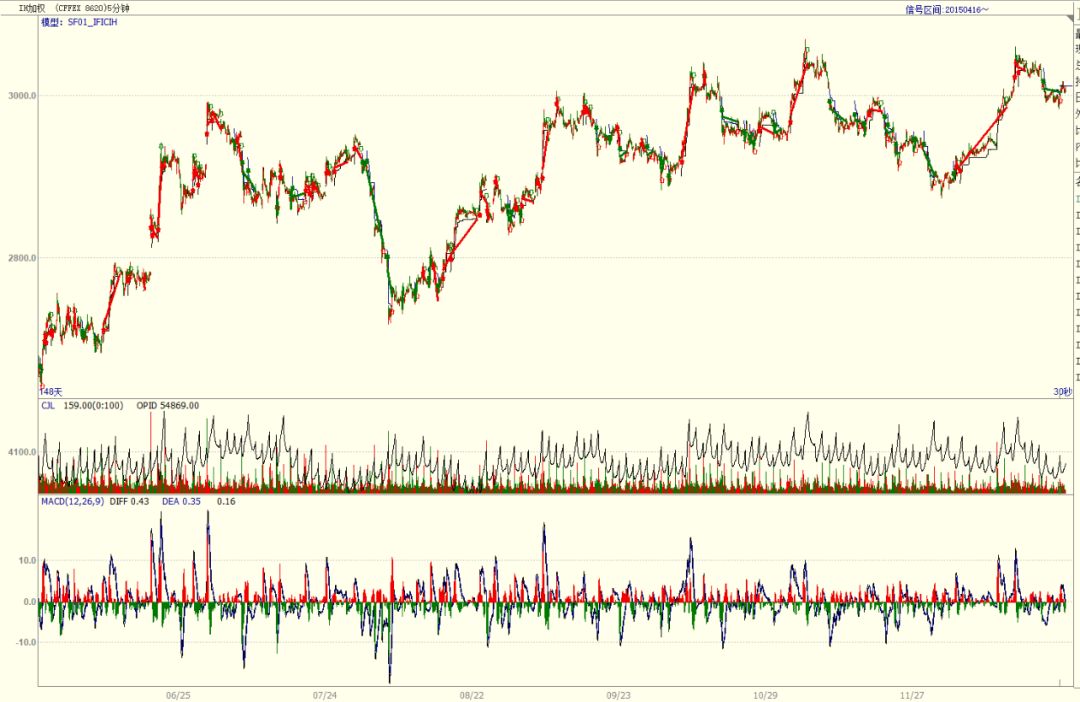
信号图:

文华8测试绩效:
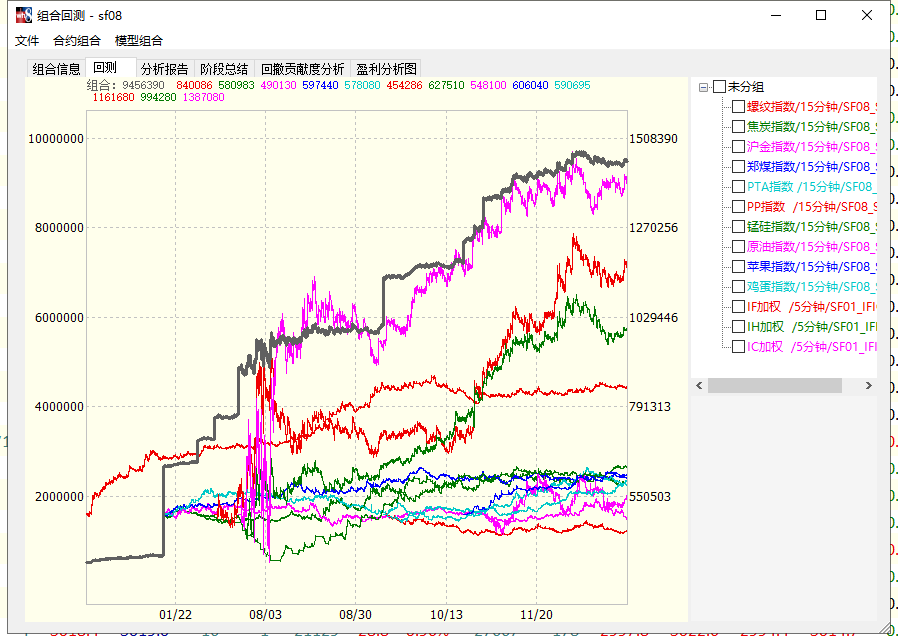

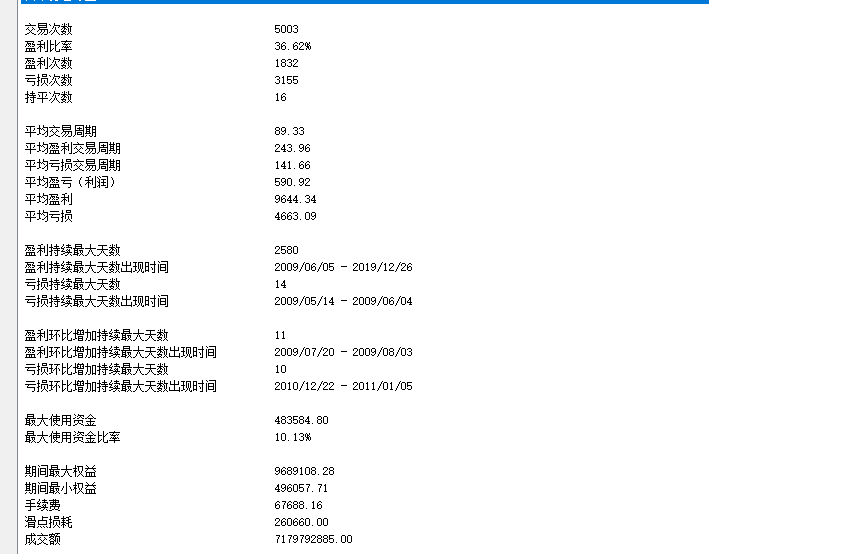
螺纹
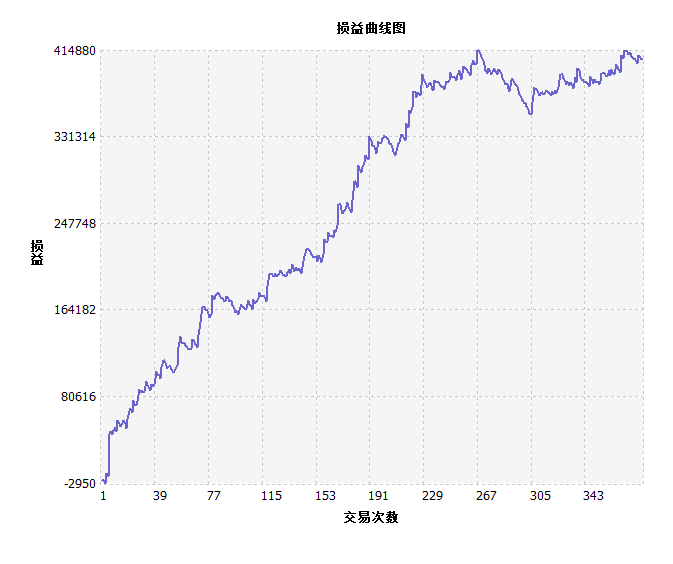
苹果
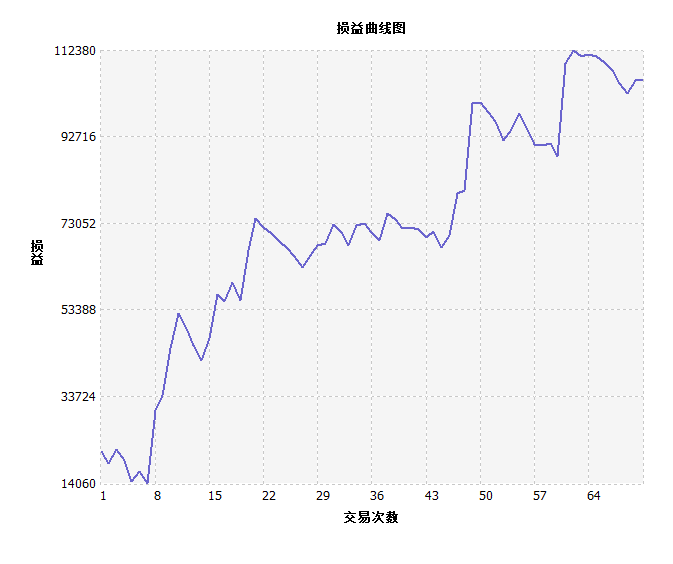
焦炭
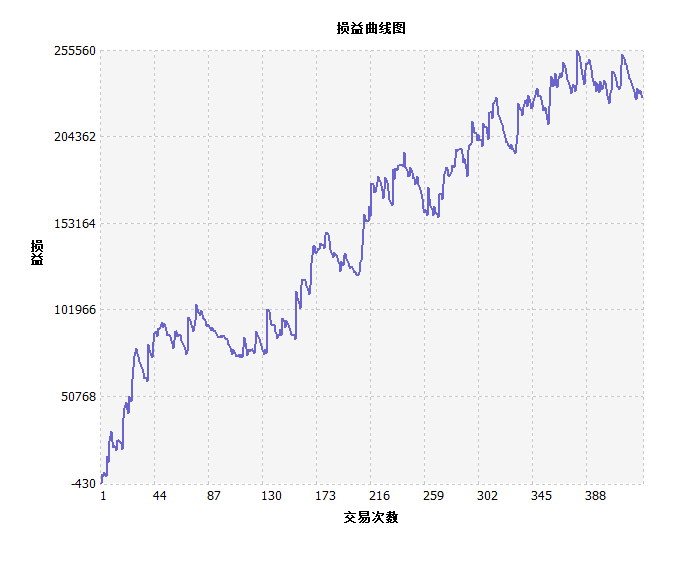
动力煤
本策略仅作学习交流使用,实盘交易盈亏投资者个人负责。

