
1、 使用 chrome 浏览器,查找网站异步请求的数据,在计算机桌面“GZ-032 竞赛文档”文件夹“XXX-02.docx(XXX 代表赛位号、02 代表任务二)”文件中创建并编写完成下表:(2 分)参考答案见下表:网页源码对应字段每个字段一致得 0.5 分;
内容网页源码对应字段酒店评分grade酒店名称hotel_name酒店星级star_level用户点评数num_comment 2、 完善 hotelscrawl.py 中内容,将函数内容截图并保存 1) 将完整的 start_requests 函数内容截图并保存;(2 分)参考答案截图:每个红框区域 一致得1 分; (两个红框共 1 分 )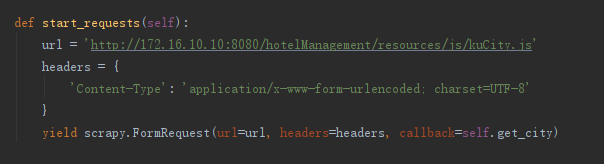 2) 将完整的 get_city 函数内容截图并保存;(5 分)参考答案截图:每个红框区域 一致得 1分; (五个红框共 5 分 )
2) 将完整的 get_city 函数内容截图并保存;(5 分)参考答案截图:每个红框区域 一致得 1分; (五个红框共 5 分 ) 3) 将完整的 get_page 函数内容截图并保存;(1 分)参考答案截图:每个红框区域 一致得 1 分;
3) 将完整的 get_page 函数内容截图并保存;(1 分)参考答案截图:每个红框区域 一致得 1 分; 4) 将完整的 get_hotel_id 函数内容截图并保存;(4 分)参考答案截图:每个红框区域 一致得 1 分; (四个红框共 4 分 )
4) 将完整的 get_hotel_id 函数内容截图并保存;(4 分)参考答案截图:每个红框区域 一致得 1 分; (四个红框共 4 分 ) 5) 将完整的 parse 函数内容截图并保存;(2 分)参考答案截图:红框区域 每行代码 一致得 0.5 分; (四行代码共 2 分 )
5) 将完整的 parse 函数内容截图并保存;(2 分)参考答案截图:红框区域 每行代码 一致得 0.5 分; (四行代码共 2 分 ) 3、 根据爬取字段,在 MySQL 中创建 crawl 数据库,根据爬虫字段,在该数据库中创建hotels 表,并查看表结构,将查看结果(含字段总行数)截图并保存;(1 分)参考答案截图:红框区域 结果一致得 得 1 分;
3、 根据爬取字段,在 MySQL 中创建 crawl 数据库,根据爬虫字段,在该数据库中创建hotels 表,并查看表结构,将查看结果(含字段总行数)截图并保存;(1 分)参考答案截图:红框区域 结果一致得 得 1 分; 4、 完善 pipelines.py 中内容,将函数内容截图并保存; 1) 将完整的 process_item 函数内容截图并保存;(1 分)参考答案截图:红框区域 结果一致得 得 1 分;
4、 完善 pipelines.py 中内容,将函数内容截图并保存; 1) 将完整的 process_item 函数内容截图并保存;(1 分)参考答案截图:红框区域 结果一致得 得 1 分; 5、 爬虫程序运行结束后查看 MySQL 数据库,按 seq 倒序排序,返回前 4 行数据,将命令与查看结果截图并保存。(2 分)参考答案截图: 每个 红框区域 结果一致得1分;(两个红框共 2 分 )
5、 爬虫程序运行结束后查看 MySQL 数据库,按 seq 倒序排序,返回前 4 行数据,将命令与查看结果截图并保存。(2 分)参考答案截图: 每个 红框区域 结果一致得1分;(两个红框共 2 分 )
![]()
![]()

