如果数据量非常大的时候,使用单一线程处理起来就会非常慢的,使用多线程来处理数据会大大提高数据处理的速度。
使用多线程读取数据的时候需要注意一个问题:就是如何避免重复读和跳读的问题,就需要使用线程安全的方式读取数据,加入线程锁。
- 重复读指的是一个以上线程读取到了同一条数据;
- 跳读指的是有些数据行没用任何线程处理。
示例代码1:
import time
import threading
import random
# 读取文件
class DataSource(object):
def __init__(self, file_name, start_line=0, max_count=None):
self.file_name = file_name
self.start_line = start_line # 第一行行号为1,按行来读取的话,对于大文件的分配处理非常有效
self.line_index = start_line # 当前读取位置
self.max_count = max_count # 读取最大行数
self.lock = threading.RLock() # 同步锁
self.__data__ = open(self.file_name, 'r', encoding='utf-8')
for _ in range(self.start_line):
self.__data__.readline()
def get_line(self):
self.lock.acquire()
try:
if self.max_count is None or self.line_index < (self.start_line + self.max_count):
line = self.__data__.readline()
if line:
self.line_index += 1
return True, line
else:
return False, None
else:
return False, None
except Exception as e:
return False, "error:" + e.args
finally:
self.lock.release()
def __del__(self):
if not self.__data__.closed:
self.__data__.close()
print("关闭读取文件:" + self.file_name)
# 业务逻辑处理
def process(worker_id, data_source):
count = 0
while True:
status, data = data_source.get_line()
if status:
print(f'线程{worker_id}获取数据,正在处理...')
time.sleep(random.randint(2, 5))
print(f'线程{worker_id}数据处理完毕')
count += 1
else:
break # 退出循环
print(f"线程{worker_id}结束,共处理{count}条数据!!!")
if __name__ == '__main__':
data_source = DataSource('text.txt')
worker_count = 10 # 开启10个线程,注意:并不是线程越多越好
workers = []
for i in range(worker_count):
worker = threading.Thread(target=process, args=(i + 1, data_source))
worker.start()
workers.append(worker)
for worker in workers:
worker.join()
print("总程序执行完毕!!!")
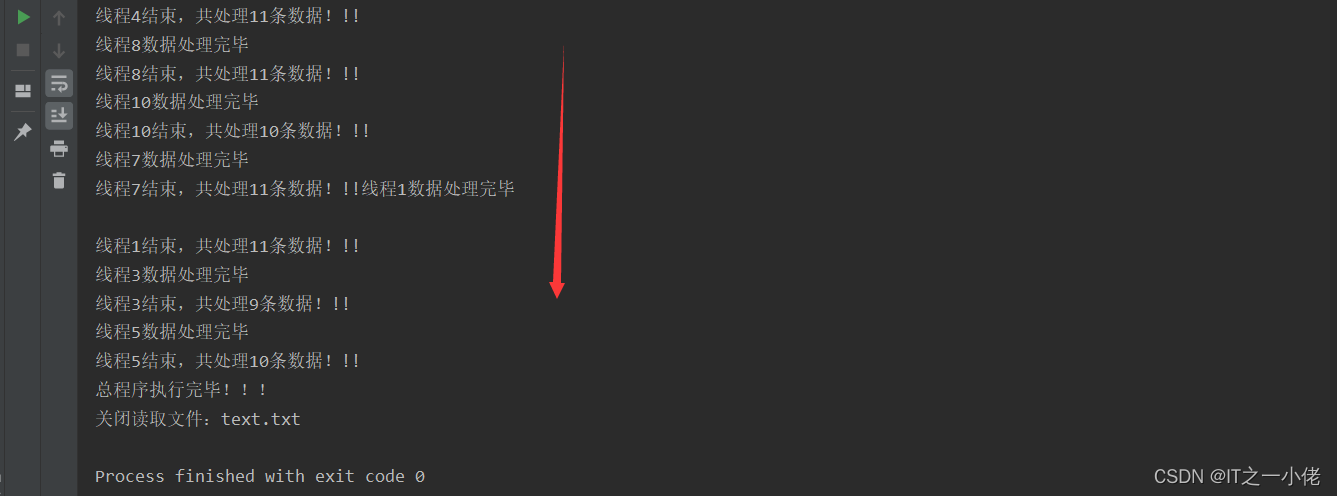
运行结果:
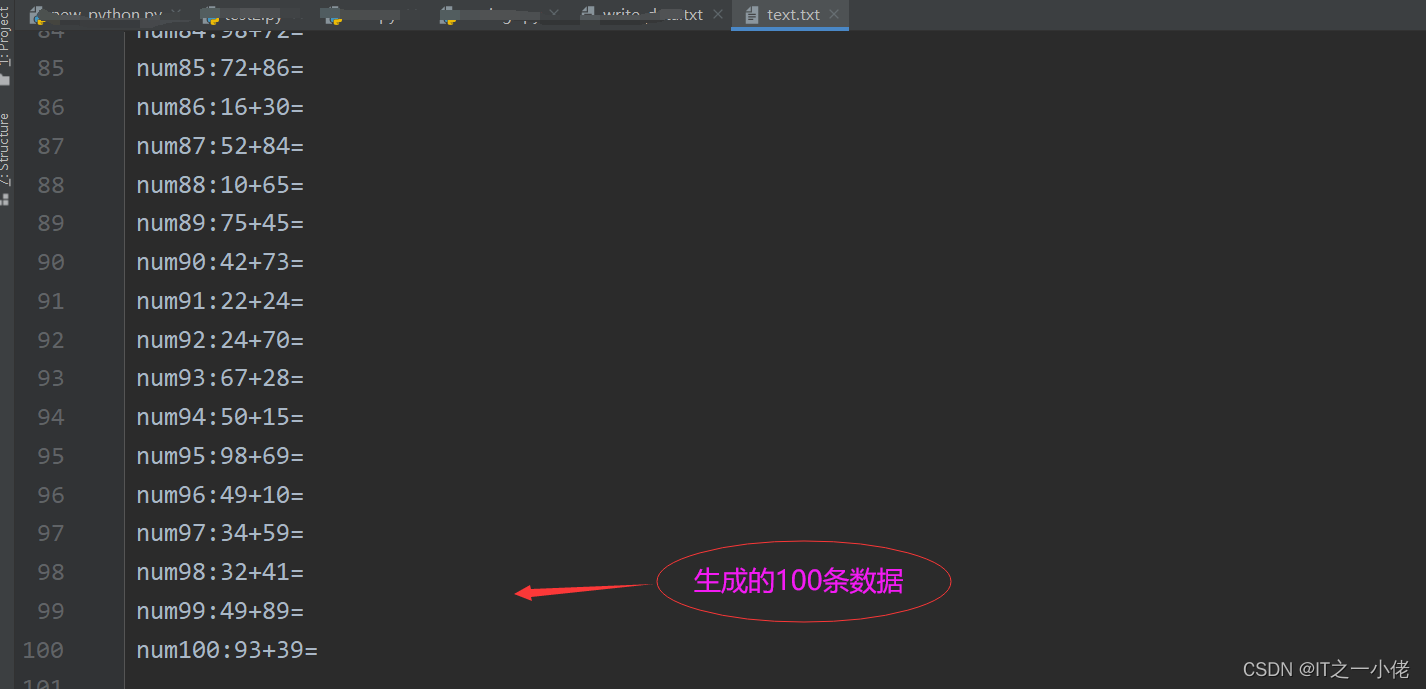
读取数据,并将处理完的数据写入文件中。
示例代码2:
generate_data.py
import random
for i in range(100):
a = random.randint(10, 99)
b = random.randint(10, 99)
data = f'num{i+1}:{a}+{b}=\n'
with open('text.txt', 'a', encoding='utf-8') as f:
f.write(data)
main.py:
import threading
# 读取文件
class DataSource(object):
def __init__(self, file_name, start_line=0, max_count=None):
self.file_name = file_name
self.start_line = start_line # 第一行行号为1
self.line_index = start_line # 当前读取位置
self.max_count = max_count # 读取最大行数
self.lock = threading.RLock() # 同步锁
self.__data__ = open(self.file_name, 'r', encoding='utf-8')
for _ in range(self.start_line):
self.__data__.readline()
def get_line(self):
self.lock.acquire()
try:
if self.max_count is None or self.line_index < (self.start_line + self.max_count):
line = self.__data__.readline()
if line:
self.line_index += 1
return True, line
else:
return False, None
else:
return False, None
except Exception as e:
return False, "error:" + e.args
finally:
self.lock.release()
def __del__(self):
if not self.__data__.closed:
self.__data__.close()
print("关闭读取文件:" + self.file_name)
# 业务逻辑处理
def process(worker_id, data_source):
count = 0
while True:
status, data = data_source.get_line()
if status:
print(f'线程{worker_id}获取数据,正在处理...')
value1, value2 = data.split('+')
result = int(value1[-2:]) + int(value2[:2])
res = data.replace('\n', '') + str(result)
# 写入文件
write_data(res)
print(f'线程{worker_id}数据处理完毕')
count += 1
else:
break # 退出循环
print(f"线程{worker_id}结束,共处理{count}条数据!!!")
# 将数据写入文件
def write_data(data, file_data='write_data.txt', mode='a'):
with open(file_data, mode, encoding='utf-8') as f:
f.write(data + '\n')
if __name__ == '__main__':
data_source = DataSource('text.txt')
worker_count = 10 # 开启10个线程,注意:并不是线程越多越好
workers = []
for i in range(worker_count):
worker = threading.Thread(target=process, args=(i + 1, data_source))
worker.start()
workers.append(worker)
for worker in workers:
worker.join()
print("总程序执行完毕!!!")
运行结果:
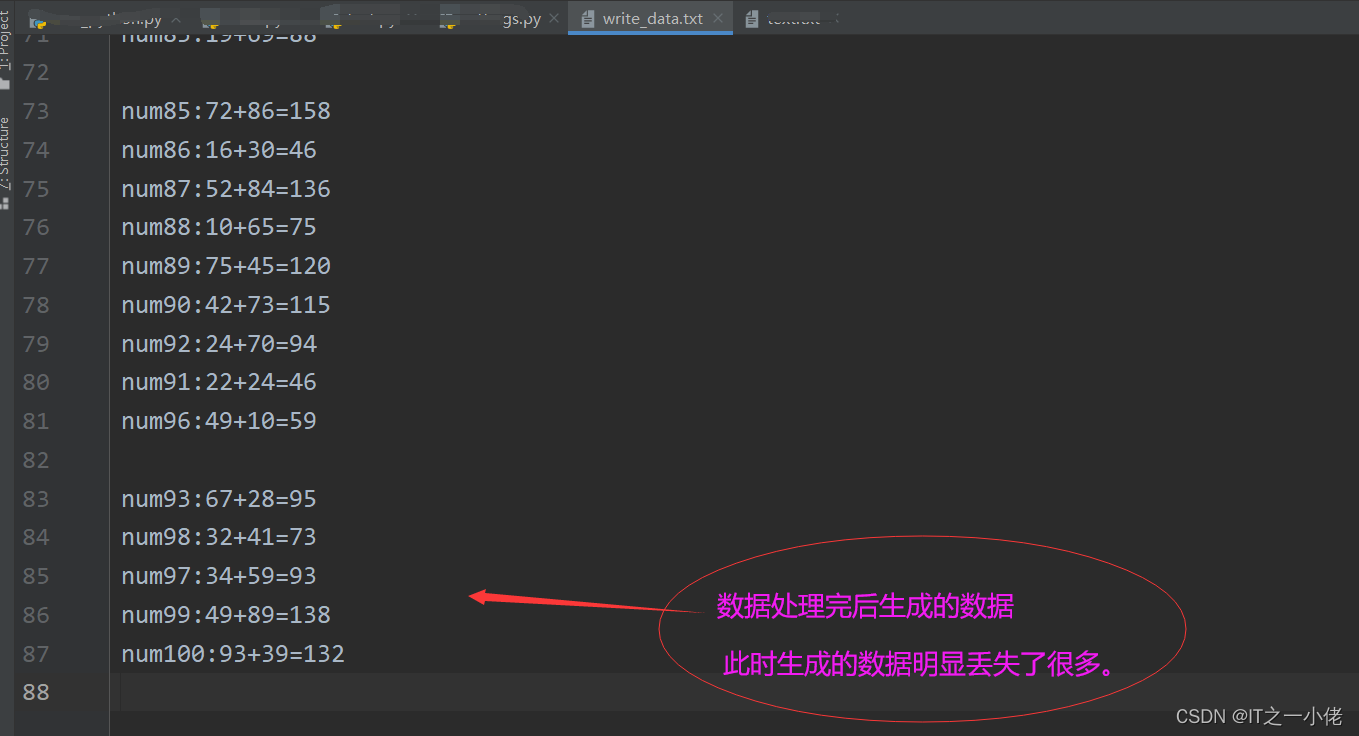
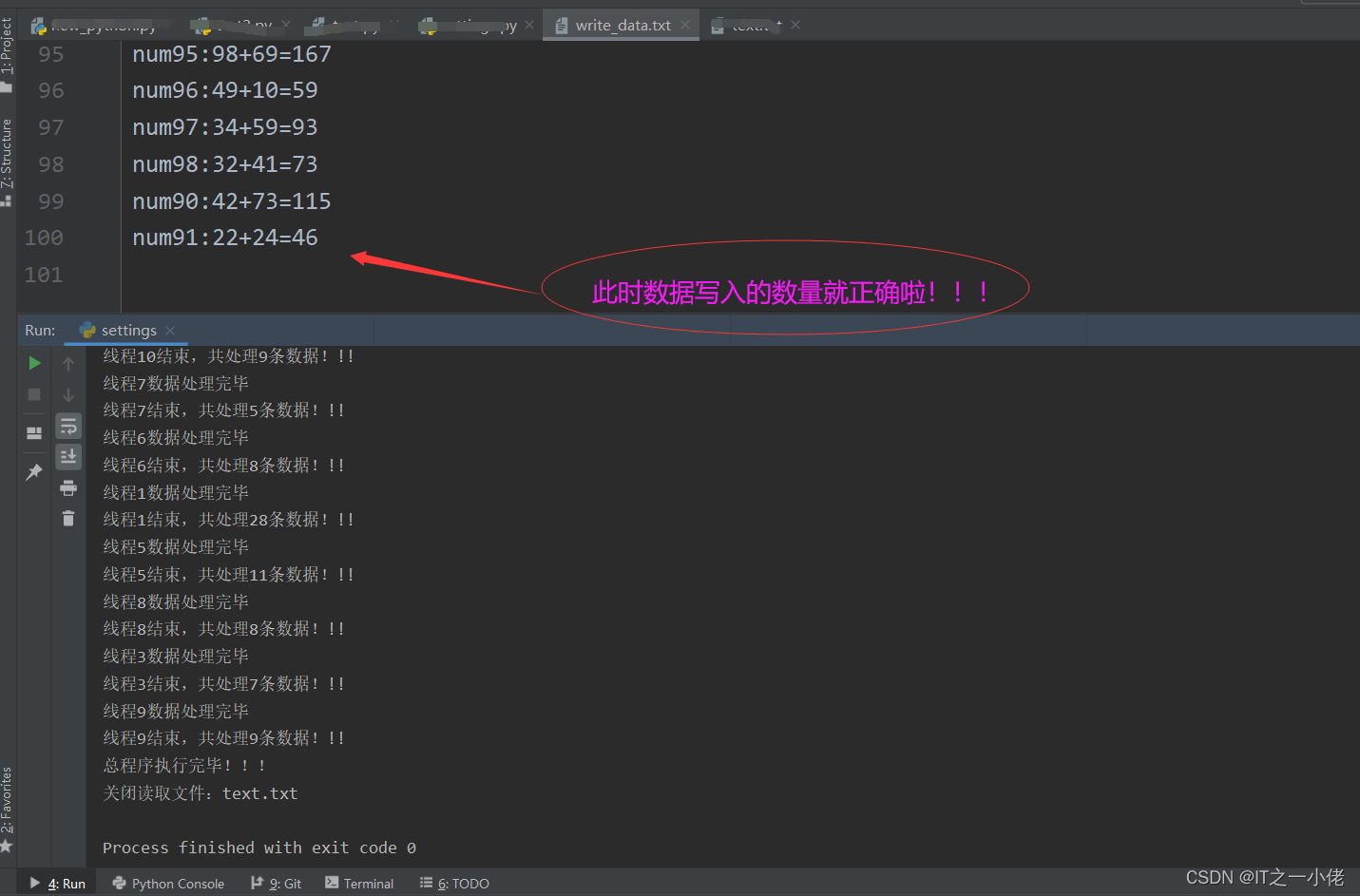
使用上述代码处理完的结果写入文档后,写入的数据却丢失的大量的数据。使用多线程写入数据时,文件中同一行数据重复写入导致有些数据丢失了。这时需要加入线程锁机制,防止数据写入丢失。
示例代码3:
import threading
# 读取文件
class ReadDataSource(object):
def __init__(self, file_name, start_line=0, max_count=None):
self.file_name = file_name
self.start_line = start_line # 第一行行号为1
self.line_index = start_line # 当前读取位置
self.max_count = max_count # 读取最大行数
self.lock = threading.RLock() # 同步锁
self.__data__ = open(self.file_name, 'r', encoding='utf-8')
for _ in range(self.start_line):
self.__data__.readline()
def get_line(self):
self.lock.acquire()
try:
if (self.max_count is None) or self.line_index < (self.start_line + self.max_count):
line = self.__data__.readline()
if line:
self.line_index += 1
return True, line
else:
return False, None
else:
return False, None
except Exception as e:
return False, "error:" + e.args
finally:
self.lock.release()
def __del__(self):
if not self.__data__.closed:
self.__data__.close()
print("关闭读取文件:" + self.file_name)
# 写入文件
class WriteDataSource(object):
def __init__(self, file_name, mode):
self.file_name = file_name
self.mode = mode
self.lock = threading.RLock()
def write_data(self, data):
self.lock.acquire()
with open(self.file_name, self.mode, encoding='utf-8') as f:
f.write(data + '\n')
self.lock.release()
# 业务逻辑处理
def process(worker_id, data_source):
count = 0
while True:
status, data = data_source.get_line()
if status:
print(f'线程{worker_id}获取数据,正在处理...')
value1, value2 = data.split('+')
result = int(value1[-2:]) + int(value2[:2])
res = data.replace('\n', '') + str(result)
# 写入文件
write_data_source.write_data(res)
print(f'线程{worker_id}数据处理完毕')
count += 1
else:
break # 退出循环
print(f"线程{worker_id}结束,共处理{count}条数据!!!")
if __name__ == '__main__':
read_data_source = ReadDataSource('text.txt')
write_data_source = WriteDataSource('write_data.txt', 'a')
# 开启10个线程,注意:并不是线程越多越好
worker_count = 10
workers = []
for i in range(worker_count):
worker = threading.Thread(target=process, args=(i + 1, read_data_source))
worker.start()
workers.append(worker)
for worker in workers:
worker.join()
print("总程序执行完毕!!!")
运行结果: