昨天学完了BeautifulSoup,爬取了诗词网,今天学了PyQuery,于是我选择爬取坑爹网 学啥用啥嘛,嘿嘿!
插个小曲:这是我qq群970353786,同在学习python,希望更多大神小白能跟我一起交流,我很多源代码也放到群里的,但是你进群问题回答print(“hello world”)结果是啥都回答不上还是不允许进。 效果:(都是动态gif的) 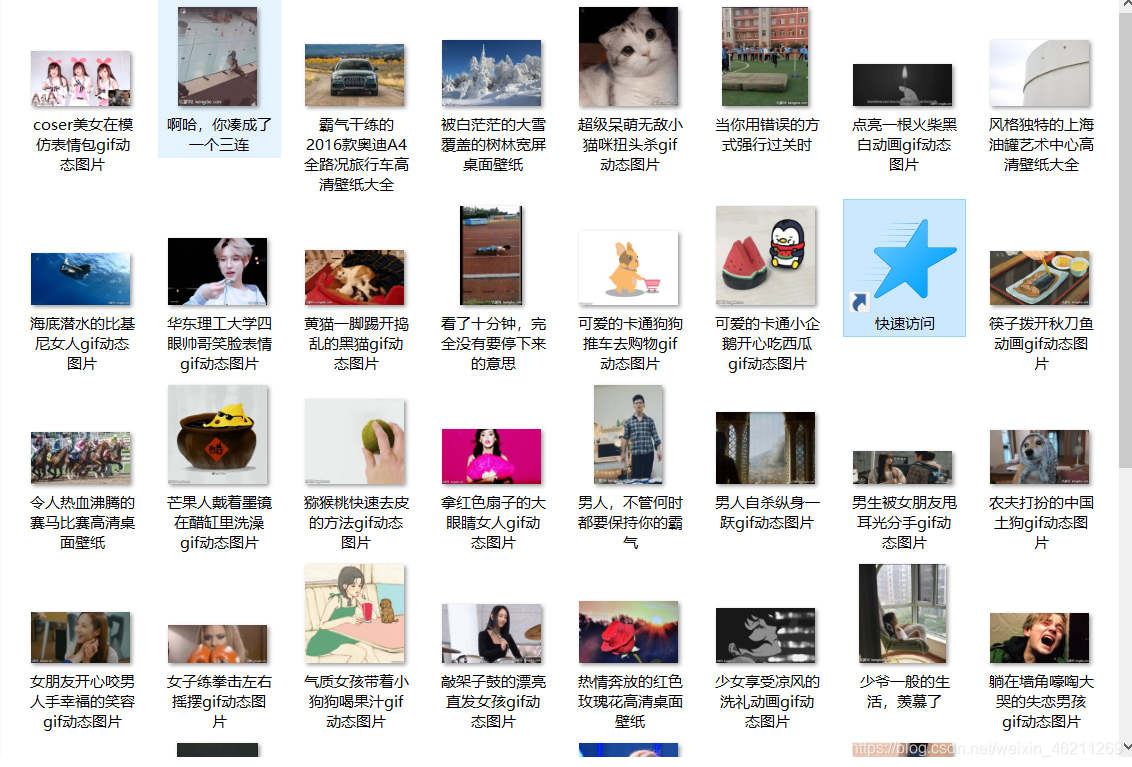
代码:(代码仅供学习参考,如果爬取内容有所侵权请联系我删除)
import requests
from fake_useragent import UserAgent
from pyquery import PyQuery as pq
headers={
'UserAgent':UserAgent().random
}
url='https://kengdie.com/'#搞笑网网址
html = requests.get(url=url,headers=headers).content.decode('utf-8')
doc=pq(html)#初始化html字符串
img=doc('.card-bg img')#获取card-bg下内容的a标签
path='D://code//my python code//爬虫//image//'
for item in img.items():
# print(item.attr('data-src'))
title=item.attr('alt')#获取标题
title=title+'.gif'
src=item.attr('data-src')#获取照片地址
src1=src.replace('mw200','large')
src2=src1.replace('thumb150','large')
response=requests.get(url=src2,headers=headers)
with open(path+title,'wb') as f:
f.write(response.content)
print('下载成功:%s'%title)
我来缕一缕PyQuery与BeautifulSoup两个模块区别: 我觉得最大的区别就是BeautifulSoup返回的东西都装在一个列表,还要去单独遍历。两者都用到了CSS选择器,确实好用,当我学到这的时候,对比下之前的正则表达式,真是简单好多了。 CSS选择器的语法参考:
https://www.w3school.com.cn/cssref/css_selectors.asp
如果对代码有问题,可以对我留言或者加群问我,我可以讲一下。


